I’ve had the opportunity to work on a number of interesting research projects during my Msc. and PhD. studies. I have developed new analysis tools and algorithms for emerging applications, built robust detection systems against sophisticated malware, designed new attacks for machine learning systems, and demonstrated the effectiveness of approaches on real systems. The system-specific core of my research has led to rewarding collaborations with researchers from program analysis, machine learning, networking, secure computation, and optimization. Here is a summary of some of my efforts.
IoT Safety, Security, and Privacy Analysis
We have developed three systems, Soteria, IoTGuard, and Saint, to analyze IoT implementations and environments for safety, security and privacy, and a toolset for IoT analysis, IoTBench.
Soteria is a static analysis system to verify whether an IoT app or IoT environment (collection of apps working in concert) adheres to relevant safety, security, and functional properties. Soteria leverages the structured nature of IoT apps to extract a state model (finite state machine) of the IoT implementation by analyzing its source code. With Soteria, we demonstrated that many apps violate safety and security properties when used in isolation and when used together in multi-app environments. This work was presented in USENIX ATC'18.
In a more recent work, we have developed a second system called IoTGuard, a dynamic system for policy enforcement on IoT devices. IoTGuard adds extra logic to an application source code to collect the application’s information at runtime. It then stores this information in a dynamic model that represents the runtime execution behavior of applications. Lastly, it enforces identified policies on the dynamic model of individual applications or sets of interacting applications. We designed two mechanisms to enforce these policies. The first mechanism blocks the device action(s) that causes the policy violation, and the second mechanism enables users to approve or deny the policy violation through runtime prompts. This work is recently accepted to NDSS'19 and will be available online soon. Through Soteria and IoTGuard, we have demonstrated that policy-based validation and enforcement in physical spaces could be effectively realized in IoT and CPS systems.
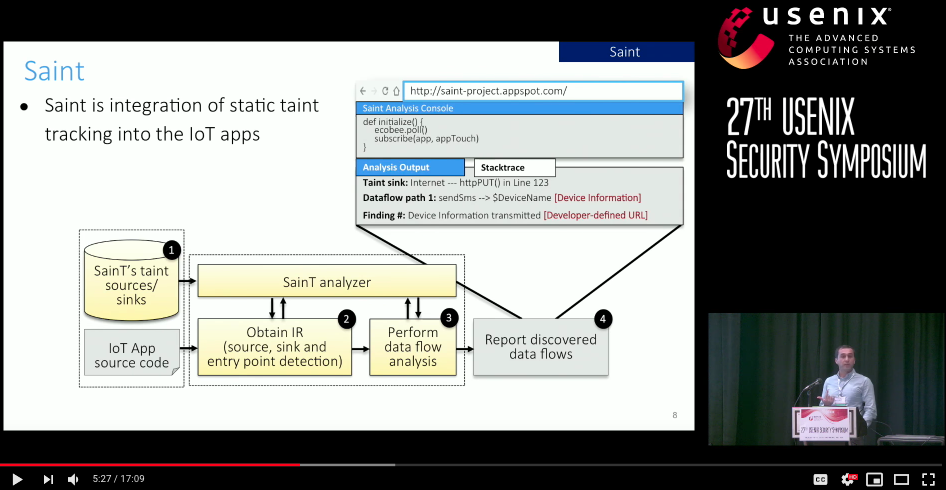
The third system is Saint, the first static taint tracking tool that finds sensitive data leaks in IoT applications by tracking information flows from taint sources (e.g., device state (door locked/unlocked)) to taint sinks (e.g., Internet and messaging services). Through this effort, we introduced a rigorously grounded framework for evaluating the use of sensitive information in IoT apps–and therein provide developers, markets, and consumers a means of identifying potential threats to security and privacy. This work appeared in USENIX Security Symposium'18.
Lastly, we have introduced IoTBench, an IoT-specific test corpus for evaluating systems designed for IoT app analyses. IoTBench is under continual development and always welcoming contributions.
My colleague, Xiaolei Wang and I created a collection of papers we recommend reading for those interested in studying Internet of Things security and privacy.
Machine Learning in Adversarial Settings
My collaborators and I investigated how existing training of Machine Learning (ML) models makes them vulnerable to adversarial samples (adversary-crafted inputs that result in misclassification). In our paper, The Limitations of Deep Learning in Adversarial Settings, we formalized the range of threat models on deep learning models and developed a novel class of adversarial sample generation algorithms based on a precise understanding of the mapping between inputs and outputs of a deep neural network. In later work, Practical Black-Box Attacks against Machine Learning, my collaborators and I showed that the transferability of adversarial examples across models enables powerful black-box attacks: the adversary may use an auxiliary model to attack a victim model without access to model parameters.
Robust Detection Models under Privileged Information
Training of models has been historically limited to only those features available at runtime. In this effort, we ask “how can detection systems integrate intelligence relevant to an attack that is available at training time, yet not available at runtime?”
Consider a rootkit detection system for mobile phones. Obtaining a set of features may drain the battery even though they contribute to the detection of a rootkit. Therefore, the users might disable the system because the battery dies very quickly. However, obtaining these features at training time is feasible as we have unlimited resources in a laboratory-based environment. We built an alternate model construction approach that trains models using “privileged” information–features available at training time but not at runtime, yet samples are classified without the need of privileged features at runtime. Turning to rootkit example, the features draining the battery are the privileged features. We showed that privileged information increases precision and recall over a system with no privileged information, including in systems such as fast-flux bot detection, malware traffic detection, malware classification, face recognition.
Our paper is accepted to ACM AsiaCCS'18: Detection under Privileged Information. Read more about its formulation and implementation in our technical report, and Feature Cultivation in Privileged Information-augmented Detection (invited paper in CODASPY IWSPA workshop).
Data Security and Privacy
Users are asked to disclose personal information such as genetic markers, lifestyle habits, and clinical history that is used by statistical models to make accurate predictions in a wide array of applications, including medicine, law, forensics, and social networks.However, due to privacy concerns, users often desire to withhold sensitive information. This self-censorship can impede proper predictions. For instance, in health care models, it may lead to serious health complications. We have developed privacy distillation, a mechanism which allows users to control the type and amount of information they wish to disclose to the providers for use in statistical models. We evaluated privacy distillation in a healthcare model for warfarin dose prediction and found that with sufficient privacy-relevant information privacy distillation retains accuracy almost as good as having all patient data. The capacity afforded by this approach allows us to make accurate predictions in a wide array of applications requiring private inputs.
Patient-Driven Privacy Control through Generalized Distillation is accepted to IEEE Privacy-aware computing (PAC) conference, 2016. The use of privacy-sensitive patient data made us develop new algorithms for Achieving Secure and Differentially Private Computations in Multiparty Settings. This paper is also accepted to PAC'16. Lastly, we have developed algorithms that allow members to define data exchange policies in a privacy-preserving collaborative machine learning to dictate their data needs. Our paper Curie: Policy-based Secure Data Exchange is accepted to ACM Conference on Data and Application Security and Privacy (CODASPY), 2019.
Network Security
In this effort, we developed a framework that uses tamper-proof features to distinguish malware traffic from traffic generated by legitimate applications. Further, we characterize the evolution of malware evasion techniques over time by examining the behavior of 16 malware families. In particular, we highlight the difficulty of detecting malware that use traffic-shaping techniques to mimic legitimate traffic and demonstrated the challenges in malware detection through traffic analysis. Read more about our study here.
In our USENIX CSET and JDMS works, my co-authors and I also take a closer look at the experimentation artifacts of malware detection. For instance, we showed that malware detection systems produce unrealistically optimistic results that arise when they mix benign traffic in a domain with attack activity recorded in another domain and designed several statistical sampling algorithms for the problem.
Science of Security
I am involved in Cyber-Security Collaborative Research Alliance (CSec CRA) with the Army Research Laboratory, Penn State, Carnegie Mellon, UC Riverside, UC Davis, and Indiana University. Our mandate is to develop a new science of security. As part of this effort, I’ve worked on the foundation for representing of operational models for cybersecurity. I developed algorithms to make optimal decisions in a cyber environment by modeling the current and future states of a cyber-operation.